 Conda
CondaConda is a popular package management system for managing dependencies of multiple languages, Python being the most popular one, and is specially used by data scientist to install dependencies for data science projects given the easy of installation of usually complicated libraries to install, specially those who depend on system-level packages and compilers. For more info about Conda look at their official documentation.
Algorithmia makes using conda environments easy by providing an Algorithmia environment
with Conda ready to be used and uses standard conda tooling such as the environment.yml spec to define the dependencies of your algorithm.
In order to use Conda to manage your dependencies you need to select it as a Language in the “Specify the environment section”, you can find “Conda” in the Dropdown. Then select the Python version you want to use.
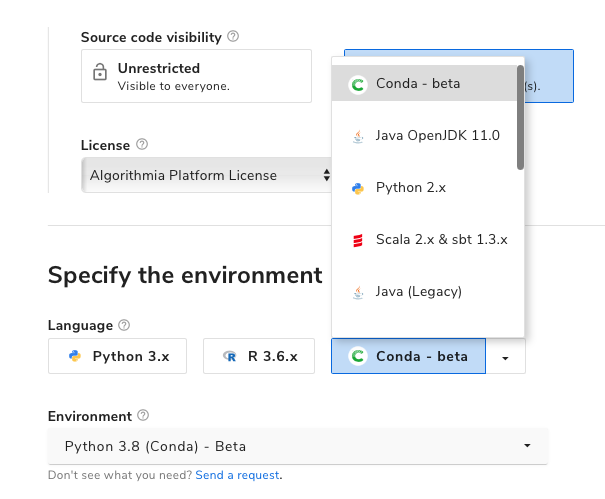
Algorithmia supports adding 3rd party dependencies coming including main anaconda repository, conda-forge, or any other valid Conda repository.
The format in which you specify these dependencies is the standard conda environment.yml file.
On the algorithm editor page there is a button on the top right that says “Dependencies”. Click that button and you’ll see a modal window, there you can specify any Conda or PyPI dependencies that your algorithm needs.
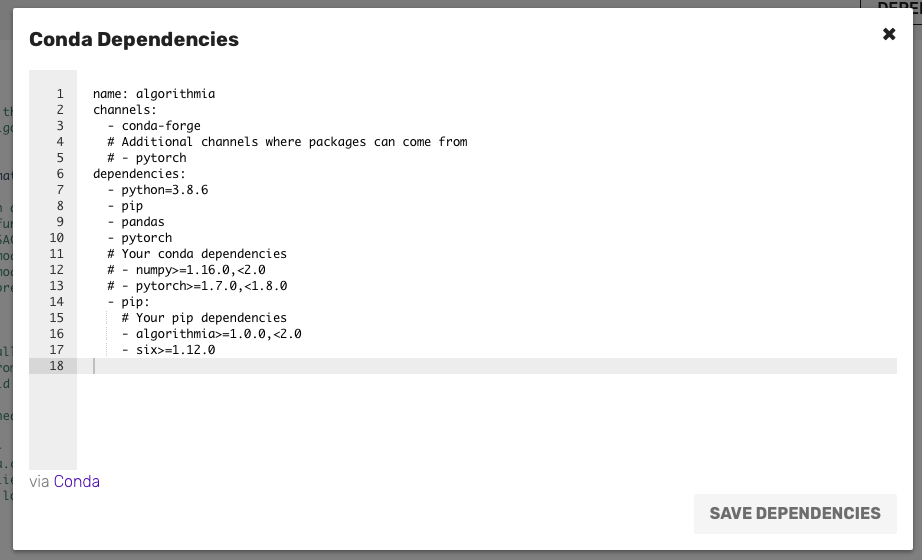
With your dependencies ready you can develop your algorithm in the same way you develop it using Python. For more information take a look at our Python documentation.
Best practices
Note that using Conda will install packages from diferent locations that are not the official Python Package Index and it’s recommended you only use Conda if you are familiar using it for local development and with the Conda package manager.
When using Conda and as a general best practice we recommend to install most packages from the same Conda repository and use as few packages from PyPI as possible as mixing those can generate some issues.