 R
RBefore you get started learning about R algorithm development, make sure you go through our Getting Started Guide to learn how to create your first algorithm, understand permissions available, versioning, using the CLI, and more.
Table of contents
- Available libraries
- Write your first algorithm
- Saving and loading R models
- Managing dependencies
- I/O for your algorithms
- Error handling
- Publishing Algorithmia Insights
- Algorithm checklist
- Publish algorithm
- Conclusion and resources
Available libraries
Algorithmia makes a number of libraries available to make algorithm development easier.
The full R language and standard library version 3.3.6 is available for you to use in your algorithms, which you can find through the “Environment” drop-down when creating a new algorithm:
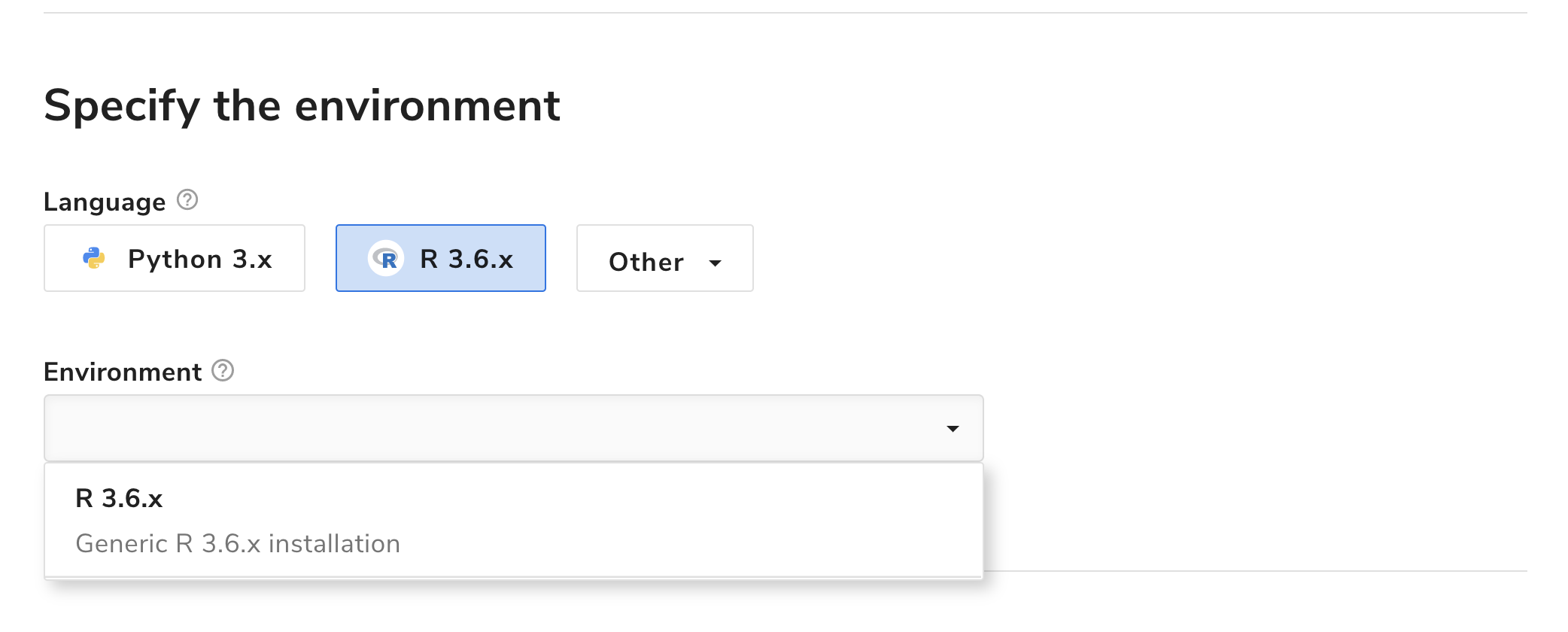
Furthermore, algorithms can call other algorithms and manage data on the Algorithmia platform via the Algorithmia R language Client.
Write your first algorithm
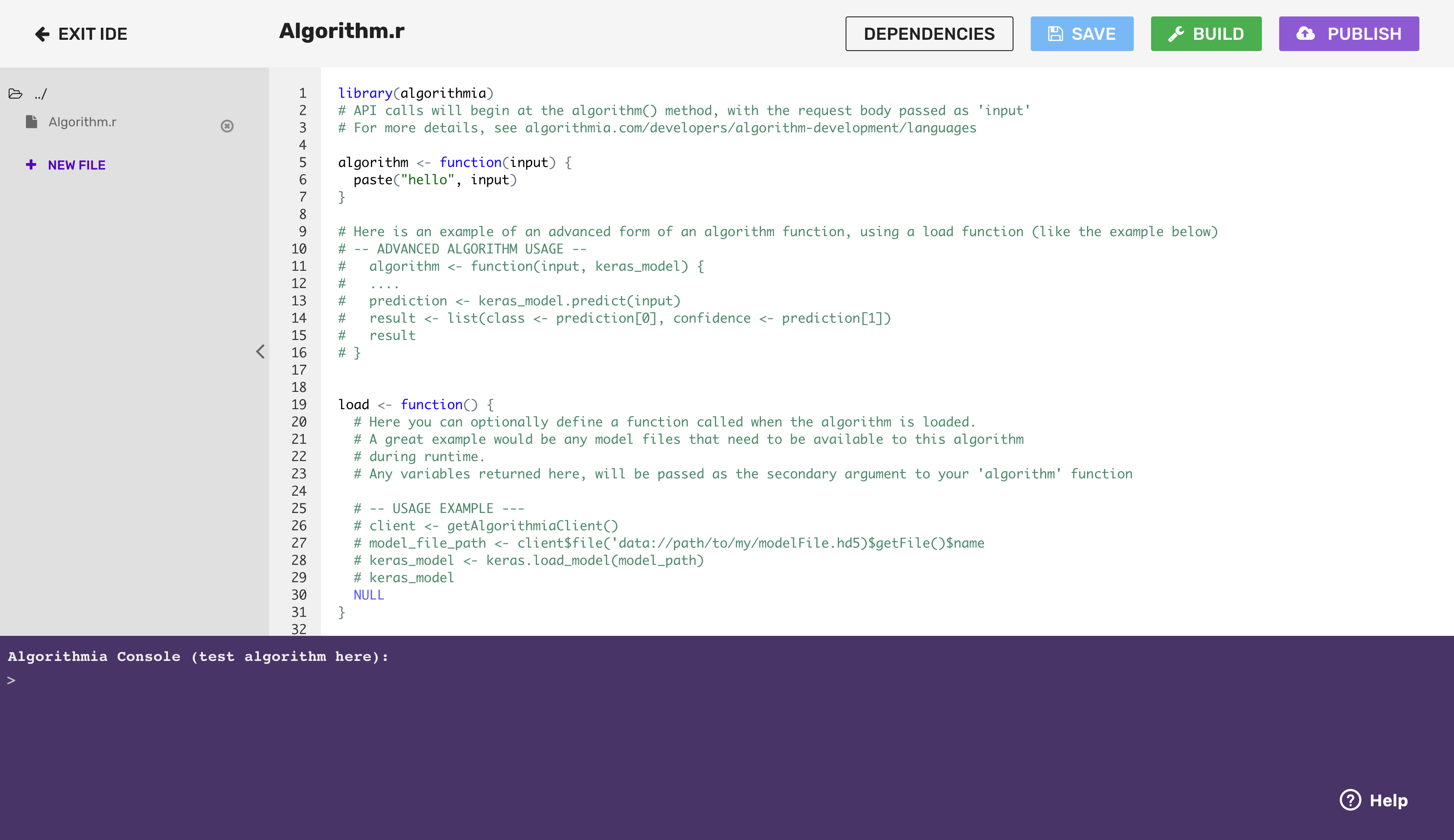
If you’ve followed the Getting Started Guide, you’ll notice in your algorithm editor, there is boilerplate code that returns “Hello” and whatever you input to the console.
The main thing to note about the algorithm is that it’s wrapped in the algorithm() function.
The algorithm() function defines the input point of the algorithm. We use the algorithm() function in order to make different algorithms standardized. This makes them easily chained and helps authors think about designing their algorithms in a way that makes them easy to leverage and predictable for end users.
Go ahead and remove the boilerplate code below that’s inside the algorithm() function because we’ll be writing a different algorithm in this tutorial:
Saving and loading R models
When you have an R model that has been serialized as an .rds file, you can deploy it easily on Algorithmia. All you need to do is save your model:
saveRDS(iris_fit_naive, "./naive_bayes_iris.rds")Then follow the instructions for how to work with data using the Data Api in the R Client Docs in order to upload your saved model to Algorithmia hosted data or you can store it in Dropbox or an S3 bucket. To find out more about working with data check out the Data Portal.
Here are a couple of demos to show you how to load your hosted .rds file inside your algorithm:
Managing dependencies
Now that you have created your algorithm, you can add dependencies.
Algorithmia supports adding 3rd party dependencies via the CRAN (Comprehensive R Archive Network) dependency file.
On the algorithm editor page there is a button on the top right that says “Dependencies”. Click that button and you’ll see a modal window:
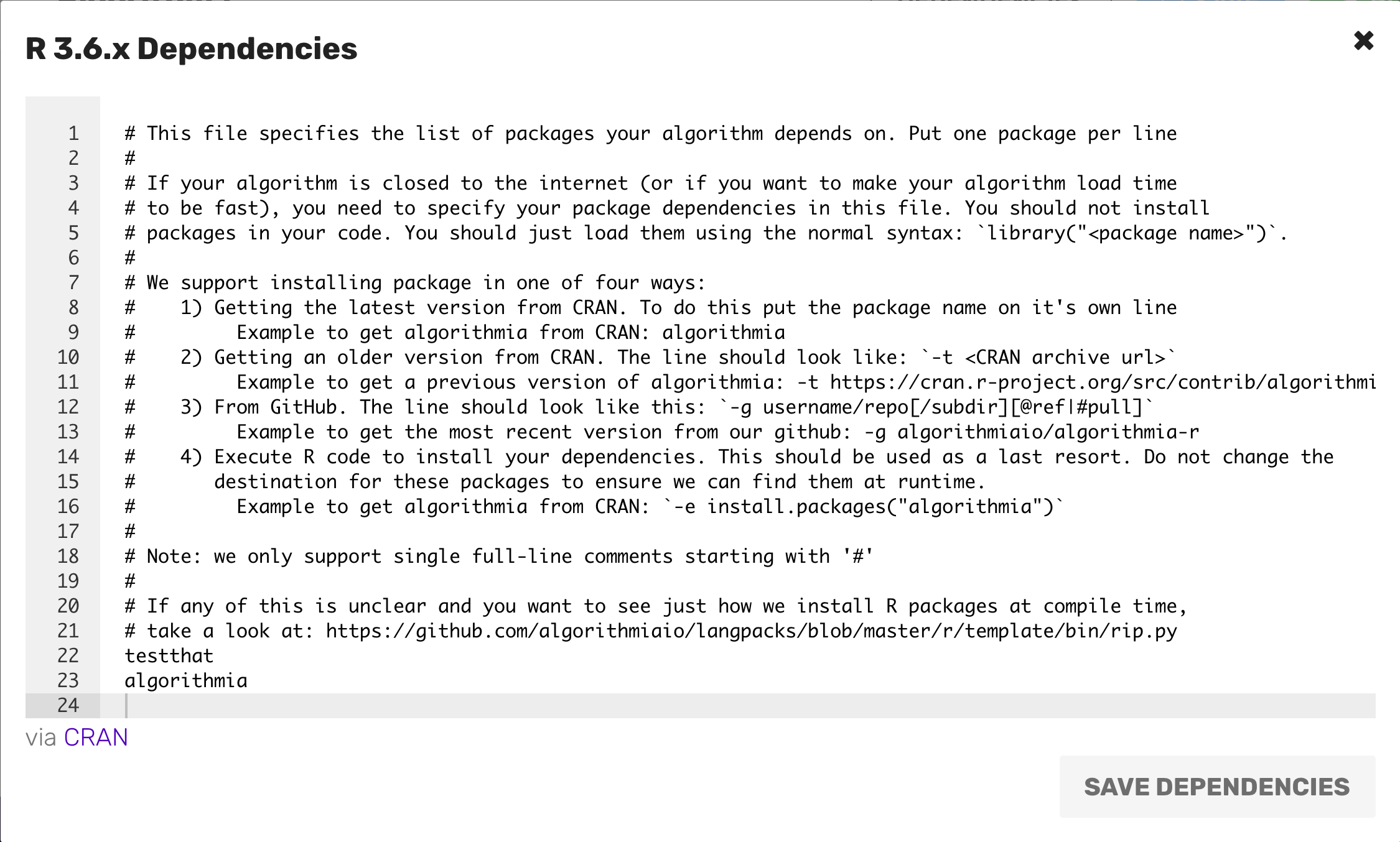
As you can see in the dependency file above, there are four different ways you can load packages in R. If you want the latest version from CRAN, than you simply type in the dependency name (this example uses the package e1071):
e1071If you wanted that same package in an older version, all you have to do is install from CRAN the exact version by finding it in the packages archive, which in this instance, should be listed in the e1071 docs found under “Old Sources”. There you’ll find the archived packages, so simply choose your version and load your dependency:
https://cran.r-project.org/src/contrib/Archive/e1071/e1071_1.6-6.tar.gzOr, if you need to pull a dependency off of GitHub instead, all you need to do is install the package with:
-g /cran/e1071Similar to how you would install through dev.tools() in R.
And finally, if you’re having issues with version conflicts, for instance package A requires version of package B while package C requires a different version of package B, then you can install with in your dependency file using install.packages():
-e install.packages(“e1071”)The last format will take longer to load the dependencies than the other formats, so it’s best to use it as a last resort.
Note, that if you do add dependencies, you will still need to import those packages via library() to your algorithm file as you would do for any R script.
For example, to make use of e1071, you would include the line:
e1071in the dependencies file and the line
library(e1071)in the main file.
The Algorithmia dependency is already installed for your convenience and relies on R version 3.3.1. For more information about Algorithmia’s R package visit: Algorithmia’s CRAN package documentation.
This guide won’t depend on any external dependencies so you can close the dependencies window.
Note: if you see an error similar to:
Error: Failed to start algorithm - Loading required package: methods
Error: package or namespace load failed...You’ll need to try and add different versions of certain R packages.
If you’re using tidyverse, add the following lines to your dependencies:
tidyverse
-t https://cran.r-project.org/src/contrib/Archive/R6/R6_2.2.2.tar.gz
-t https://cran.r-project.org/src/contrib/httr_1.3.1.tar.gz
-t https://cran.r-project.org/src/contrib/jsonlite_1.5.tar.gz
withrIf you still get an error, try a different version directly from the CRAN archives:
tidyverse
-t https://cran.r-project.org/src/contrib/Archive/R6/R6_2.2.2.tar.gz
-t https://cran.r-project.org/src/contrib/Archive/httr/httr_1.4.0.tar.gz
-t https://cran.r-project.org/src/contrib/Archive/jsonlite/jsonlite_1.5.tar.gz
withrFor dplyr, use:
dplyr
-t https://cran.r-project.org/src/contrib/Archive/R6/R6_2.2.2.tar.gz
withrIf you’re using both caret and nnet in the same Algorithm add:
caret
-t https://cran.r-project.org/src/contrib/Archive/R6/R6_2.2.2.tar.gz
-t https://cran.r-project.org/src/contrib/nnet_7.3-12.tar.gzI/O for your algorithms
Now let’s get started on the hands-on portion of the guide:
The first algorithm that we’ll create will take a JSON formatted object passed as input by the user which is deserialized into a R list before the algorithm is called.
It will output a JSON formatted object which the user will consume with an API call to the algorithm path which is found at the bottom of the algorithm description page.
This path is based on your Algorithmia user name and the name of your algorithm, so if you are “demo” and your algorithm is “TokenizeText”, then the path for version 0.1.1 of your algorithm will be demo/TokenizeText/0.1.1
Note that Algorithmia uses rjson to automatically (de)serialize input and output for you. If you are used to using jsonlite or another JSON package, certain datastructures (especially matrices and dataframes) will be structured differently in the I/O. We recommend reviewing this excellent guide which explains the differences.
Working with basic data structures
Below is a code sample showing how to create an algorithm working with basic user input.
You’ll also see some error handling within the algorithm, but we recommend that you take a look at our Better Error Handling Guide for more information.
library(algorithmia)
# Note that you don't pass in your API key when creating an algorithm
client <- getAlgorithmiaClient()
# Create a generic error function
AlgorithmError <- function(error){
stop(error, call. = FALSE)
}
algorithm <- function(input){
# Finds the minimum and maximum numbers.
tryCatch({
if(typeof(input) == "list" & length(input$numbers) > 1){
user_max <- max(input$numbers)
user_min <- min(input$numbers)
return(list(min_num = user_min, max_num = user_max))
} else {
print("Please pass in a valid input")
}
}, error = function(e) {
AlgorithmError(paste("Please pass in a valid input", "\n", e))
}
)
}Go ahead and type or paste the code sample above in the Algorithmia code editor after removing the “Hello World” boilerplate code.
Now compile the new code sample and when that’s done test the code in the console by passing in the input and hitting enter on your keyboard:
{"numbers": [1, 4, 2, 6, 3]}You should see the minimum and maximum of the numbers in the list returned in the console:
{"max_num":6, "min_num":1}Working with data stored on Algorithmia
This next code snippet shows how to create an algorithm working with a data file that a user has stored using Algorithmia’s Hosted Data Source.
Files stored in Hosted Data must be transferred into the algorithm before use, via the getFile method. Alternately, their contents can be transferred using getString, getJson, or getBytes.
Prerequisites
If you wish to follow along working through the example yourself, create a text file that contains any unstructured text such as a chapter from a public domain book or article. We used a chapter from Burning Daylight, by Jack London which you can copy and paste into a text file. Or copy and paste it from here: Chapter One Burning Daylight, by Jack London. Then you will can upload it into one of your Data Collections.
This example shows how to create an algorithm that takes a user’s file which is stored in a data collection on the Algorithmia platform. It then splits up the text into sentences and then splits those sentences up into words:
library(algorithmia)
client <- getAlgorithmiaClient()
# Create a generic error function
AlgorithmError <- function(error){
stop(error, call. = FALSE)
}
algorithm <- function(input){
tryCatch({
# Download contents of file as a string
if (client$file(input$user_file)$exists()) {
# Get the contents of the file as a string.
text <- client$file(input$user_file)$getString()
sentences <- strsplit(text, "[.]")
# Split up each sentence into words.
words <- strsplit(unlist(sentences), "[ ]")
print(words)
}
}, error = function(e) {
AlgorithmError(paste("Please pass in a valid input", "\n", e))
})
}After you paste the above code into the Algorithmia code editor you can compile and then test the example by passing in a file that you’ve hosted in Data Collections.
Following the example below replace the path to your data collection with your user name (it will appear already if you are logged in), data collection name, and data file name which you can find under “My Collections” in Data Collections:
{"user_file": "data://YOUR_USERNAME/data_collection_dir/data_file.txt"}The code above with return both the original text and the sentence split up into words.
This guide uses a chapter from the public domain book Burning Daylight, by Jack London, but for brevity we’ll only show the first sentence in “text” and “words”:
{"text": "It was a quiet night in the Shovel.", "words": [['It', 'was', 'a', 'quiet', 'night', 'in', 'the', 'Shovel']]}When you are creating an algorithm be mindful of the data types you require from the user and the output you return to them. Our advice is to create algorithms that allow for a few different input types such as a file, a sequence or a URL.
Working with JSON data
Note that we use the rjson package to parse JSON within your algorithm.
Working with directories
While running, algorithms have access to a temporary filesystem located at /tmp, the contents of which do not persist across calls to the algorithm. While the Data API allows you to get the contents of the files you want to work with as JSON, a string, or raw bytes, in some cases you might need your algorithm to read and write files locally. This can be useful as a temporary location to store files downloaded from Hosted Data, such as raw data for processing or models to be loaded into your algorithms. It can also be used to write new files before uploading them via the Data API.
For reference, this gist provides an example of iterating over data in a directory, processing it, and writing new data to a file, while this template for ALBERT and Tensorflow provides an example of using the /tmp directory to load a model.
Writing files for the user to consume
Sometimes it is more appropriate to write your output to a file than to return it directly to the caller. In these cases, you may need to create a temporary file, then copy it to a Data URI (usually one which the caller specified in their request, or a Temporary Algorithm Collection):
# {"target_file":"data://username/collection/filename.txt"}
file_uri <- input$target_file
tempfile <- sprintf("/tmp/%s.tmp",UUIDgenerate())
save_some_output_to(tempfile)
client$file(file_uri)$putFile(tempfile)Calling other algorithms and managing data
To call other algorithms or manage data from your algorithm, use the Algorithmia R Client which is automatically available to any algorithm you create on the Algorithmia platform. For more detailed information on how to work with data see the Data API docs.
You may call up to 24 other algorithms, either in parallel or recursively.
Here is an example of creating an algorithm that relies on data from another algorithm:
library(algorithmia)
client <- getAlgorithmiaClient()
# Create a generic error function
AlgorithmError <- function(error){
stop(error, call. = FALSE)
}
scrape_web <- function(input){
# Call algorithm that returns main text content from a URL.
tryCatch({
algo <- client$algo("util/Url2Text/0.1.4")
if ("URL" %in% names(input) & startsWith(input$URL, "http") || startsWith(input$URL, "https")) {
response <- algo$pipe(list(input$URL))$result
return(response)
}
}, error = function(e) {
AlgorithmError(paste("Please pass in a valid input", "\n", e))
})
}
algorithm <- function(input){
tryCatch({
# Take user input of URL and return text as words.
text = scrape_web(input)
# Split text into lists of sentences
sentences = strsplit(text, "[.]")
# Split up each sentence into words
words <- strsplit(unlist(sentences), "[ ]")
print(words)
}, error = function(e) {
AlgorithmError(paste("Please pass in a valid input", "\n", e))
})
}This should return a split up list of strings:

As you can see from these examples, fields that are passed into your algorithm by the user such as scalar values and sequences such as lists, dictionaries, tuples and bytearrays (binary byte sequence such as an image file) can be handled as you would any Python data structure within your algorithm.
For an example that takes and processes image data check out the Places 365 Classifier’s source code.
Error handling
In the above code examples we showed how to create an AlgorithmError function which you should use for handling errors within your algorithm. This way the user can tell the difference between a standard R library error and an error thrown by your algorithm:
AlgorithmError <- function(error){
stop(error, call. = FALSE)
}And then raise the error with a helpful error message:
tryCatch({
# Run your code
}, error = function(e) {
AlgorithmError(paste("Please pass in a valid input", "\n", e))
})If you are creating an algorithm that relies on calling another algorithm you may use Algorithmia error messages for catching errors thrown by that algorithm:
algo <- client$algo("util/Url2Text/0.1.4")
# Try calling without valid input
algo$pipe(list())$error$messageFor more information on error handling see the Better Error Handling Guide.
Publishing Algorithmia Insights
This feature is available to Algorithmia Enterprise users only.
Inference-related metrics (a feature of Algorithmia Insights) can be reported via the report_insights method of the Algorithmia client. For example, to report a list:
# Report Algorithmia Insights
client$report_insights(list(faces_in_image=4)})Algorithm checklist
Before you are ready to publish your algorithm it’s important to go through this Algorithm Checklist and check out this blog post for Advanced Algorithm Development .
Both links will go over important best practices such as how to create a good algorithm description, add links to external documentation and other important information.
Publish algorithm
Once you’ve developed your algorithm, you can publish it and make it available for others to use.
On the upper right hand side of the algorithm page you’ll see a purple button “Publish” which will bring up a modal:
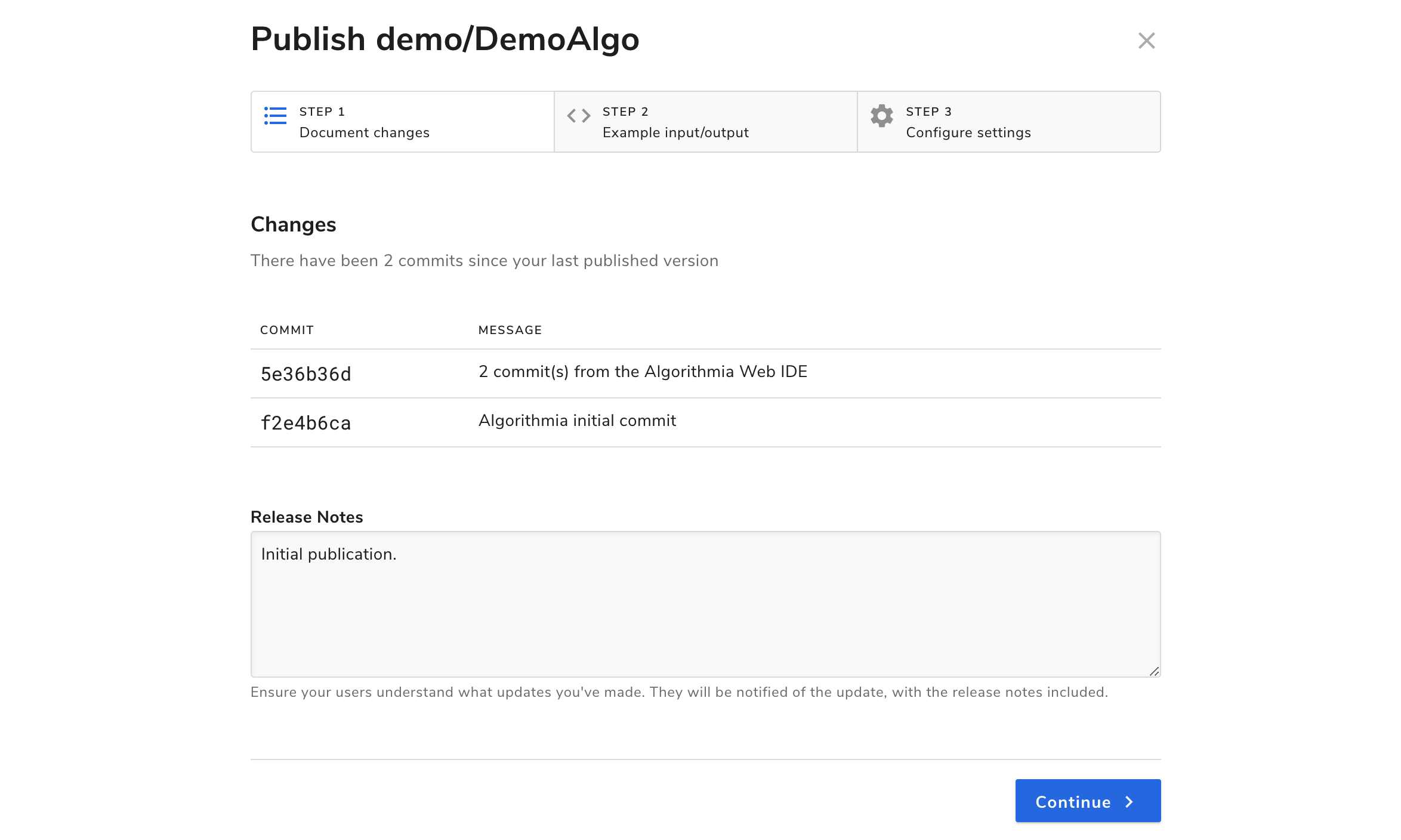
In this modal, you’ll see a Changes tab, a Sample I/O tab, and one called Versioning.
Changes shows you your commit history and release notes.
Sample I/O is where you’ll create your sample input and output for the user to try under Try the API in the Run tab. When you add a sample input, make sure to test it out with all the inputs that you accept since users will be able to test your algorithm with their own inputs.
Under the Versioning tab, you can select whether your algorithm will be for public use or private use as well as set the royalty. The algorithm can either be royalty-free or charge per-call. If you opt to have the algorithm charge a royalty, as the author, you will earn 70% of the royalty cost.
Check out Algorithm Pricing for more information on how much algorithms will cost to run.
Under Semantic Versioning you can choose which kind of release your change should fall under: Major, Minor, or Revision.
If you are satisfied with your algorithm and settings, go ahead and hit publish. Congratulations, you’re an algorithm developer!
Conclusion and resources
In this guide we covered how to create an algorithm, work with different types of data and learned how to publish an algorithm.