Q3 2021 Release Notes
The following features are available in Algorithmia LTS version 21.1.13.
New API Documentation
We’ve migrated our static API documentation to a framework based on the open-source tool Redoc. The new API docs are rendered dynamically from your cluster-specific API spec file at https://CLUSTER_DOMAIN/v1/openapispec. When you view your cluster-specific API docs at https://CLUSTER_DOMAIN/developers/api, you’ll now be viewing only the functionality available in your deployed version of Algorithmia. As before, cURL and Python code samples are shown for select endpoints.
The new docs are available beginning in Algorithmia version 21.1.13 and immediately at our public API docs site. Note that the public API docs include only a subset of endpoints available to enterprise customers, as not all features are included in our multi-tenant offering.
Q2 2021 Release Notes
The following features are available in Algorithmia LTS version 21.0.
New Platform Guides
Glossary
We’ve created a brand new Glossary page to help explain the technical terminology we use across our platform. In addition to describing various Algorithmia-specific features, the glossary provides definitions for some common terms used more generally in the industry, so that you can better understand the language of MLOps. Where appropriate, glossary terms also define string placeholders that we’ll be incorporating into code samples across our documentation and user interface in order to provide a clear mapping between the glossary terms and the code you use to interact with resources on our platform.
Integrations
Our brand new Integrations page contains descriptions of Algorithmia’s many documented integrations with third-party tools, services, and frameworks. The page serves as a starting point for understanding the natively integrated features that are available to you on the Algorithmia platform, as well as some of the patterns we’ve documented for using services and tools that don’t have built-in integrations. From this page you can quickly access relevant documentation and assess which services might be most suitable for your Algorithmia workflows based on your current tooling and IT considerations.
Third-Party Secret Provider Plugins
We’re excited to announce that we now have documented example implementations of secret provider plugins for Hashicorp Vault and Azure Key Vault. This enables Algorithmia Enterprise customers to use their existing accounts in these third-party vaulting systems to store and manage their sensitive data, and for their Algorithmia algorithms to access those secrets at run time. To use this feature, a cluster administrator must first configure the new secret provider by uploading the secret provider plugin module through the Secret Store page in the admin panel.
Algorithm Execution Errors
Non-admin users can now view algorithm execution errors from the last seven days for specific algorithms or from all algorithms they’ve called. These error logs can also be retrieved through the Algorithmia API.
All errors are captured and included in the error log, allowing users to debug with a single glance. Errors from algorithms called in a pipeline are bubbled up to the top-level calling algorithm. Error details include timestamp, error type, execution metadata, stacktrace, and partial algorithm input.
This feature is disabled by default and can be enabled globally on an Algorithmia cluster by a cluster administrator.
Algorithm-specific errors
Each algorithm’s execution errors are displayed on the algorithm’s profile page in a dedicated tab. Errors are only visible to users who are viewing an algorithm they own or that’s owned by an organization of which they’re a member.
Account-level errors
Algorithm execution errors are displayed on each user’s account profile page in a dedicated tab. These errors are only visible to users viewing their own profile page (i.e., the profile page for the account into which they’re authenticated), and are only shown for algorithms that they’ve called using an API key they own.
Advanced Reporting for Governance
The Advanced Reporting for Governance feature provides administrators the ability to view resource usage on the platform. Usage can be viewed at four different levels depending on your access permissions. If you’re an organization administrator, you can explore reporting at the organization and account level, and even down to the individual algorithm level. Cluster administrators are granted all of the above permissions, as well as being able to view reporting at the cluster level. We’ll start at the top level of the cluster roll-up.
Cluster-level reporting
Only cluster administrators have access to cluster-level reporting. To use this feature, navigate to the “Governance Reporting” page in the administrator panel.
As a first step, we recommend you add your hardware cost rate estimates to ensure you get accurate cost estimates based on your resource usage. To do this, click the “Resource Cost Rates” button in the top-right corner to view the values. To add or modify existing values, click the “Edit Values” button and input your values in the form. Submit your changes when you’re done and you’ll see cost estimates displayed in the report. Once you’re satisfied with the cost estimates, you can dive into the data. Note that only cluster administrators have access to set or modify cost rates, which are set at the cluster level.
On the Advanced Reporting page, you’ll notice dropdowns to specify exactly which data you want to see. The first dropdown determines the date range, the next two determine how to group and filter the data, and the final dropdown determines the direction of ordering. These dropdowns determine which data are displayed in the plot as well as how those data are ordered in the table below. You’ll notice many grouping and filtering options available to help you determine the “who”, “what”, “when”, “how much”, and “how long” of platform resource usage. Finally, if you need to save, distribute, or export these metrics for use in another application, there’s a button to download a CSV of all data for the selected time period.
Organization-level reporting
Organization administrators have a subset of the permissions granted to cluster administrators. Namely, they can view resource usage data for the organizations for which they’re an administrator, the accounts that are members of those organizations, and the algorithms owned by those organizations.
To view Advanced Reporting at the organization level, navigate to the organization’s profile page and click on the “Reporting” tab, which is only visible to administrators. Here you’ll see the same options for filtering and displaying data as listed above for cluster-level reporting, but it’ll be pre-filtered to only show data for that specific organization.
To view Advanced Reporting at the account level, navigate to the account’s profile page and click on the “Reporting” tab, which is only visible to administrators. Here, you’ll see the same options for filtering and displaying data but it’ll be pre-filtered to only show data for that specific account.
To view Advanced Reporting at the algorithm level, navigate to the algorithm’s overview page and click on the “Reporting” tab, which is only visible to administrators. Here, you’ll see the same options for filtering and displaying data but it’ll be pre-filtered to only show data for that specific algorithm.
GitLab, Bitbucket Cloud, and Bitbucket Server Source Code Management Integrations
We’ve added three new source code management (SCM) integrations: GitLab, Bitbucket Cloud, and Bitbucket Server. These new integrations expand on our current SCM integration with GitHub Enterprise. By using a single source of truth for your machine learning codebase, you can now take advantage of all the enhanced governance and management features that GitLab and Bitbucket Cloud’s CI/CD workflows offer, and with the Bitbucket Server integration, you can do your development work in the SCM system that you’re most comfortable using.
Once your cluster administrator configures a connection to an SCM provider, you can immediately create algorithms backed by a Git repository on that provider.
With the implementation of GitLab, Bitbucket Cloud, and Bitbucket Server SCM integrations, users can now easily connect their hosted repositories to their Algorithmia accounts, which provides a seamless workflow from development to production. Customers that use these third-party SCM providers can leverage engineering best practices such as code reviews and dependency audits to ensure consistencies between development and production code, and CI/CD workflows to increase automation and testing of MLOps pipelines.
Algorithmia Event Flows with Kafka
We’ve just released a new way to create event-driven algorithm workflows using Apache Kafka, a cloud-agnostic open-source message broker. Now your team’s data scientists and application developers can easily enable Kafka event-driven jobs in a user-friendly workflow while providing your cluster administrators with more granular control over who has access to connect to your Kafka broker. Among other things, Algorithmia Event Flows enable automation of workflows from model monitoring to retraining, enabling you to optimize the performance of your models in production. If you don’t already use Kafka, contact us to learn more about your options for getting started.
To enable event-driven workflows using Kafka, a cluster administrator must first configure a connection to a Kafka broker—this can be any externally hosted Kafka cluster. Once that step is completed, any member of an organization can create dynamic event-driven algorithm workflows. For instance, if you have a pipeline that requires data pre-processing, you can use Algorithmia Event Flows to run a data transformation algorithm on new data as it streams into your Kafka topic. That same algorithm can then publish the processed data to a completely different Kafka topic. Further down the pipeline, you can set up another algorithm to subscribe to that second topic, and it will ingest the cleaned data as its payload.
Application developers and data scientists can now easily enable Kafka event-driven algorithm workflows to create rich data and inference pipelines. Using our streamlined user interface, they can view the available event workflows that their Algorithmia cluster administrator has configured for their organization-owned algorithms.
Information security teams can be confident that the credentials used to connect to their Kafka brokers are only used by their Algorithmia cluster administrators, and that no other user can connect to or configure that broker.
Cluster administrators will also have a rich user interface to view the available organization-owned algorithms that are on the cluster and restrict the ability of specific algorithms to subscribe or publish data to a Kafka Topic to enhance the ability to control and audit data and machine learning pipelines.
Q1 2021 Release Notes
Introduction
Our latest release includes a variety of new features that primarily focus on improving the governance and security of machine learning operations (MLOps) in a wide range of enterprise environments. These features further bolster our commitment to providing enterprise-grade security and governance across all data, models, and infrastructure. With the new features, enterprise customers will also get expanded capabilities to help them monitor and optimize the performance of their ML models in production. These new features are available to all Algorithmia Enterprise customers.
Enhanced security features
We’re proud to share that we’ve expanded our security features to provide even greater protection for your business.
Secret Store for external resources
We’ve created a vault-based Secret Store, enabling you to create and manage credentials in a central location for access to data sources and web services. This will allow you to provide access to resources without the need to expose credentials or share them amongst the users that require access to sensitive information. Additionally, integrations with third-party vault tools to integrate with your internal vault implementation are being added.
SSO upgrades
We now offer support for single sign-on (SSO) and Security Assertion Markup Language (SAML), allowing for a user’s login credentials to provide them access to multiple resources. This makes it possible for identity providers to securely pass authenticated identities and their attributes to service providers.
We’ve also added Active Directory (AD) group synchronization to enable a centralized location for administering a user’s permissions and providing access to shared resources. This simplifies identity and access management, allowing for synchronization of organization membership, and granting of permission to resources on the cluster, based solely on the tags present in a user’s SAML assertion.
Lastly, new JSON Web Tokens (JWT) now provide verification through JSON Web Key Sets (JWKS) to support transmitting data between parties as a JSON object. This will provide users with the ability to authenticate via single sign-on, and then use a JWT to make authenticated requests to resources on the cluster.
Q3 2020 Release Notes
Introduction
This is an exciting release for Algorithmia Enterprise as we continue to deliver new and significant capabilities for our customers. Notably, this release focuses on advanced model governance and operational management with Algorithmia Insights. Additionally, customers can reach even higher scale, performance, and infrastructure efficiency with our new autoscaler and scheduler technology.
Algorithmia Insights
Algorithmia Insights is a flexible integration solution for ML model performance monitoring. It provides access to algorithm inference and operational metrics, making it easy to integrate into any monitoring, reporting, and alerting tool.
Algorithmia Insights allows customers to emit a rich metrics payload from every prediction, including model operational metrics (execution time, timestamp, request ID) and customized model inference metrics such as data inputs and prediction outputs. Customers can then integrate those metrics via Kafka into nearly any external logging, monitoring, or data visualization system.
Enabling Algorithmia Insights
Algorithmia Insights is available to Enterprise customers for deployments scheduled after the feature release date of October 30 and will be included in Enterprise subscriptions.
To enable Algorithmia Insights, your cluster administrator can follow the administrator docs to learn how to configure the connection to Kafka. After your cluster administrator has connected to Kafka, algorithm creators can enable Algorithmia Insights with a click of a checkbox when publishing their algorithm. It’s that easy to then view all the algorithm metrics that have been enabled in monitoring and alerting tools such as DataDog, InfluxDB, New Relic, Grafana, Kibana, and more.
Monitoring, alerting, and taking action based on Algorithmia Insights
Many organizations today don’t have the ability to monitor model performance, and those that do use a patchwork of disparate tools and manual processes for monitoring and reporting on ML model performance in production often without critical data required to satisfy stakeholder requirements. Algorithmia Insights enables you to:
- Identify and correct model drift, data skews, and negative feedback loops
- Quickly detect underperforming models and mitigate model decay
- Identify and alert when models need to be retrained
- Comply with internal and external audits and regulations
- Reduce risk of model failure
With Algorithmia Insights, you can use the monitoring and alerting tools of your choice, with no vendor lock-in. You have control over the data you choose to emit, and the system you connect to. You can access your metrics via Kafka and connect it to a real-time monitoring or alerting tool, or check out Kafka Connect to learn how to export your metrics offline to do analysis later.
New autoscaler and scheduler
What has set us apart from other ML platforms in the market today is our ability to manage algorithm execution at scale. With this release, we have taken scaling to a whole new level by providing more robust worker management and algorithm execution pipelining, resulting in dramatically higher throughput and efficient worker utilization. Along with these performance and operational improvements comes new administrator pages, Grafana dashboards, and alerts.
Administrators will now be able to:
- View workloads to optimize performance
- View execution details in the new Algorithm Execution admin page
- Filter and sort workers
- View GPU memory usage for an algorithm
- Utilize new alerts to ensure thresholds are being enforced
- Configure GPU limits
This release will provide more insight into algorithm execution as well as the controls to fine-tune the platform to meet performance needs. This will result in higher throughputs with existing hardware, as well as decreases in cold start latency.
Q2 2020 Release Notes
Introduction
We are pleased to present several new features and upgrades this quarter, most notably around security and governance of machine learning systems. This release showcases advanced security options that enable customers to operate Algorithmia in restrictive environments, including AWS C2S, AWS GovCloud, VMware, authenticated proxies, customer-provided OS images, private Docker registries, private dependency mirrors, and private certificate authorities.
This new version of Algorithmia Enterprise also includes support for the latest AWS and Azure GPU hardware, user local debugging improvements, and integration to PyCharm.
Algorithmia now allows local debugging in the desktop tools developers use today. We want our users’ workflows to be seamless: they can write and run local tests for algorithms, pass local data files as input to algorithms, and integrate with development environments like PyCharm. Integrations like these allow developers to use flexible tooling and develop faster with fewer defects.
Azure event listeners
This feature enables event listeners on Azure clusters that listen to Azure Service Bus queues and is designed for enterprise customers using Azure who are looking to integrate Service Bus queue triggered execution capabilities into their ecosystem. Event listeners allow the user to trigger algorithm executions with payloads from messages in an Azure Service Bus queue.
Enterprise customers will see the feature enabled with their quarterly update. All necessary configurations are documented in the Azure Listeners section in our dev center.
The feature is in the main algorithm dashboard under tab event listeners, and listeners can be created from the “Create New” dropdown menu at top right. An event listener is created for a published version of the algorithm. The listener is listening to a specified queue and whenever a message is received from the queue, the listener executes the algorithm with the message payload as the input.
Algorithm environments
We have improved the way algorithm runtime environments are built, tested, and provided to users, by creating a new system to deliver environments and languages that can be executed within an Algorithmia cluster; we’ve ensured that these environments can be executed in any enterprise cluster.
Using the feature
For admins
Algorithm Environments are maintained by Algorithmia, and can be imported into a given cluster through the admin panel. Cluster administrators can choose to import any environment available in the list to their cluster based on the needs of their users and security concerns for the operator.
Admins will see a new page for Algorithm Environments, which will allow them to import these new languages.
Once logged into Algorithmia, navigate to the Admin Panel and click on “Add Environment” to see the list of available environments; then click on the desired environment(s) to add, and then click “Add Environment” to import it.
By selecting and adding the environment, your users will be able to create algorithms using that installed environment. If you have not added the environment from the list, your users will not be able to view that environment or create an algorithm using that environment.
The specified environment will now be available in the list of environments, and details can be viewed by clicking on a specific one.
Non admins
When making new algorithms, users will see language options that are now called Environments.
Improved debugging of algorithms (local and UI)
This feature improves users’ local debugging experience by updating error messages, enabling users to write and run local tests for cloned algorithms, and passing in local data files as input to the algorithms. Our new integration with PyCharm means users can also use an effective and familiar debugging tool for algorithm development.
Enabling users to pass in their local data file into the Python Client will make it faster to test algorithms locally before production.
Using the feature
Set up a local development environment, including installing the Algorithmia Python Client in PyCharm. Full directions for integrating Algorithmia with PyCharm is in the Developer Center under Advanced Algorithm Development.
Clone an algorithm from GitHub or Algorithmia in PyCharm, pass in the local file path when running it for testing, then write and run the unit test file.
Latest hardware support
With advances in machine learning, we need to provide our enterprise customers with the latest hardware to take advantage of their cutting-edge capabilities. We are proud to have an initiative that evaluates and supports the latest hardware to meet the demands and performance our customers have come to expect. We are excited to announce the next generation of hardware support with even more to come very soon.
Below comprises the list of new instances:
- AWS general purpose EC2 M5 instance designed for the most demanding workloads. M5’s provide a 14-percent better price/performance over the M4 instances on a per-core basis.
- AWS EC2 P3 instances provide high-performance GPUs explicitly designed to accelerate machine learning, using up to one petaflop of performance per instance.
- AWS EC2 G4 instances provide the most cost-effective AWS instance for deploying machine learning models in production. G4 instances utilize NVIDIA T4 GPUs and Cascade Lake CPUs optimized for machine learning inference to reduce latency.
- Azure NCsv2-series virtual machines are a new addition to offered GPUs (NVIDIA Tesla P100), providing more than 2 times the current NC-series in computational performance.
- Azure’s NCsv3-series virtual machines provide the next generation GPUs (NVIDIA Tesla V100) of the NCsv2-series GPUs (NVIDIA Tesla P100), with 1.5 times faster computational performance.
- Azure’s NDs-series virtual machine is a new GPU addition, specially designed for AI and deep learning workloads with larger memory sizes (24gb) powered by NVIDIA Tesla P40 GPUs.
SSO enhancements
Algorithmia supports several authentication options for Enterprise customers. Additional configuration options are now available for integration with Single Sign On solutions via OpenID Connect and LDAP.
Enterprise customers who integrate with a Single Sign On solution via OpenID Connect or LDAP can now also choose whether to restrict browsing of the platform only to authenticated users, and whether to disable local username/password authentication.
UNILOG
Want to know what’s going on in your cluster? Need access to raw information for debugging incidents? Is proactive alerting of errors to your cluster admins important? Ever wish as a cluster admin that you could hook into your existing tools for collecting and aggregating log data? Have you ever hoped you could see product usage and trends?
UNILOG is an administration tool for easily accessing debug log information (or flowing into an external log collection system) for the Algorithmia platform and compute infrastructure. Not only will UNILOG give you a deeper understanding of what is happening in the Algorithmia platform, but it will also provide our on-call staff the ability to assist our enterprise customers in fine-tuning or resolving any issue that may arise. Another part of it is a saved query system that provides an automated way to execute queries on log data to generate metrics and alerts. UNILOG has a web-based user interface for viewing and searching debug log information for the Algorithmia platform.
Additionally, cluster administrators can configure their Algorithmia installation to send debug logs to the log collection tool of their choice (any with a syslog integration).
Using the feature
Cluster administrators can access the UNILOG interface from the left sidebar of the web user interface, under the “Admin” heading. Additionally, the Administrator Manual has instructions for connecting the Algorithmia platform to an external log collection system via syslog.
Collecting debug log information is significantly faster and easier for cluster administrators, saving them much time and effort when debugging issues.
Entity model update
We have taken a different approach to how we store and access algorithms. The Entity Model Update project provides UUID for algorithms, users, and hosted collections to decouple the algorithm from entity owners and entity names. Hosted data collections can now be assigned to the algorithm as default and accessed via data://.algo/default.
Calling algorithms, performing builds, and other CRUD operations that were previously only available through a combination of owner/algorithm name will now be accessed by the algorithms UUID as well as the ability to assign algorithms to hosted collections by default.
On Premises InfoSec Compliance
For On-premises VMware enterprise customers, we have enhanced our offering to meet the increasing InfoSec expectations. Algorithmia Enterprise can now be installed using our own hardened CentOS or RHEL host images. Additionally, the installation can be performed from an environment that does not allow internet access enabling Algorithmia Enterprise to run in highly restricted on-premises environments. Learn more from your account representative.
Administrative updates
We have several new monitoring dashboards for cluster databases, cluster services, and request access is added for administrators. These new dashboards allow cluster administrators to have clearer insight into how their clusters are functioning to help with resource management, cluster activity, capacity planning, and troubleshooting or debugging.
Using the features
The administrator Grafana panel now contains four new dashboards, Service Proxy, MySQL, Pyrometer, Web Server, and API Server, that show these new metrics.
The new MySQL database dashboard allows cluster administrators to see detailed metrics about usage of the internal MySQL database that stores information for the Algorithmia cluster’s operations.
The new Service Proxy dashboard allows cluster administrators to see detailed metrics about inbound requests to the cluster and their response times.
The new Pyrometer, Web Server, and API Server dashboards allow cluster administrators to see detailed metrics about database resource usage, JVMs, and infrastructure.
Q1 2020 Release Notes
Introduction
2020 is going to be a big year at Algorithmia. We are working on features that empower our customers in tooling flexibility, connectivity, security, and ML management so they can focus on extracting value from ML.
Our first release of 2020 comprises a diverse feature set that increases the options our customers have for frictionless ML deployment and model auditing. Several of these features are iterations on previously released features because we want to continuously strive for more for our customers.
Q1 Features
- Source Code Management – GitHub Integration
- Newest on-premises offering – VMWare
- Platform Usage Reports
Source Code Management
We are pleased to announce that we have expanded our source code management offering to include GitHub, adding to the benefits of a centralized code repository and increasing ML portability! By connecting your Algorithmia and GitHub accounts, you can store your source code on GitHub and deploy it directly to Algorithmia. It’s that simple.
Once enabled by your administrator, you will be able to select a GitHub (or GitHub Enterprise) instance when creating an algorithm, which will create a new GitHub repository for your algorithm.
All updates to the repository’s default branch will automatically precipitate new builds for your algorithm. By leveraging GitHub with Algorithmia, algorithm developers can leverage existing GitHub workflows they already have and access the entire suite of GitHub features, including GitHub Actions, and still ensure that source code visibility is restricted to those with proper GitHub permissions.
Where to learn more
Algorithmia administrators can learn more about integrating GitHub with Algorithmia here. Once configured, users need simply select the GitHub repository host when creating an algorithm:
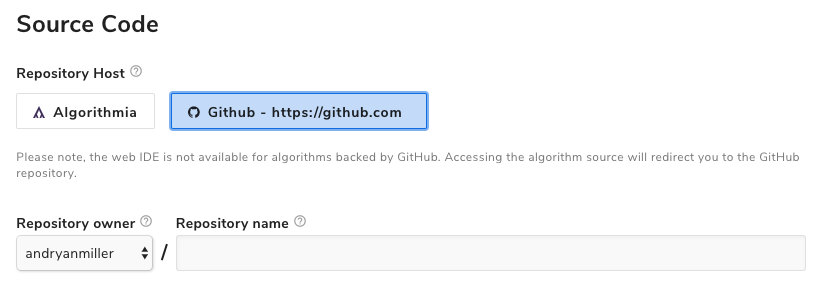
This feature is available now in our deployment and will ship to users during this release.
Newest on-premises offering: Algorithmia on VMWare
Algorithmia’s newest on-premises offering, VMWare, means multi-cloud ML deployment across public and private clouds is a reality. Algorithmia Enterprise for VMWare allows customers to run Algorithmia in their own VMWare infrastructure.
Enterprise customers can benefit from serving and running models in their data centers for compliance, regulatory, IT policy, or security use cases where AE for AWS or Azure are not viable. Our VMWare edition of Algorithmia Enterprise is deployable on either existing or new VMWare compute and storage infrastructure. Customers bring their VMs, raw storage, and network connectivity, and we provide the rest.
This feature is ideal for customers who want to use Algorithmia Enterprise in their own datacenter, especially if they are existing VMWare users.
Talk to us about how AE for VMWare fits into your organization’s data center strategy!
Algorithmia Enterprise for VMWare is available to all enterprise customers now.
Platform Usage Reports
Given a customizable date range (which defaults to the past 7 days), users can now view platform usage from three different perspectives: all usage, algorithms, and users.
You asked and we delivered.
We are now empowering our customers with increased model auditing tools. Usage Reports provide clear visibility into how the ML platform is used.
Select a preset date range or input a custom date range to display all activities/usage of the platform, including:
- model consumption
- compute duration
- caller information
- hardware (CPU/GPU) use
Reports are presented in the UI, and selecting a metric provides a detailed list of the model execution results. Administrators can also download the reports as a CSV file.
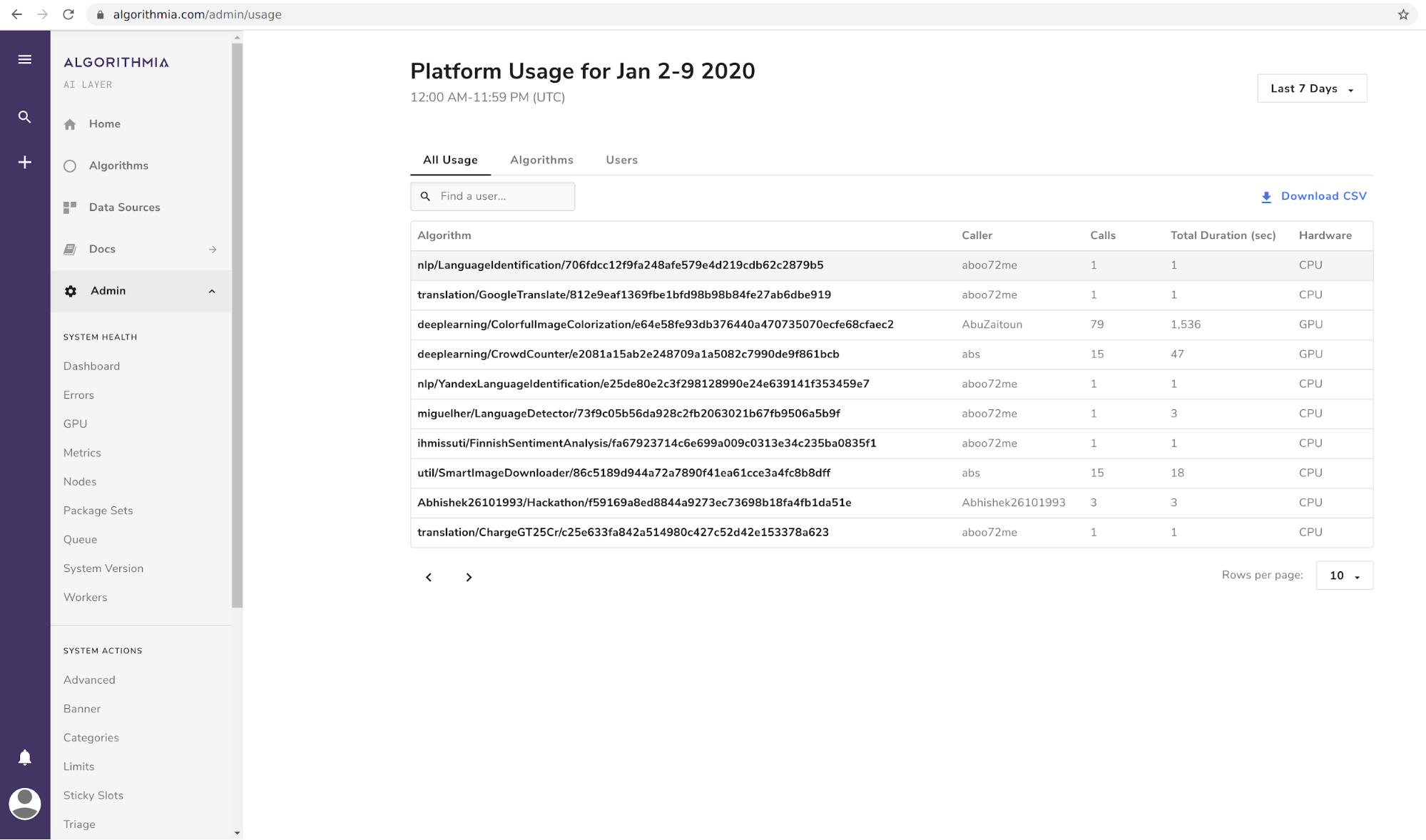
All Usage
This tab shows information grouped by the username/algorithm tuple. That is, it shows which users called which algorithms and the number of times they did so (along with hardware, computer time, and other metrics).
When you click on a row in the all usage table, you will see the complete set of columns:
- algorithm: algorithm display name
- version: hash version of the exact algorithm called
- caller: which user called the algorithm
- owner: user who created and owns the algorithm
- total calls: total number of calls the calling user made to this algorithm in the date range
- total duration: total number of seconds the algorithm ran for caller in the date range
- total errors: total number of failed calls to this algorithm the caller made in the date range
- error duration: total number of seconds the algorithm ran for calls in which it returned an error (for this caller)
- hardware: whether the algorithm runs on a CPU or GPU instance
One caveat to the total compute time: each call is rounded up to the nearest second. For instance, if in the given date range, a user calls a certain algorithm twice, and the first call took 2.04 seconds and the second call took 2.08 seconds, the total time for those two calls is 4.12 seconds, which the table will round up and display as 5 seconds.
Also note that if a call takes less than one second, the call’s duration will be rounded up to a full second. So calling Hello World 23 times would most likely result in a total duration of 23 seconds being displayed. The motivation for this is that in the public version of Algorithmia we only charge by credits. One credit = one second, so if a user makes a call that lasts less than a second we still charge for the full second.
Algorithms
This tab shows usage information grouped at the algorithm level. That is, it shows which algorithms were called and how many times (total across all users) they were called.
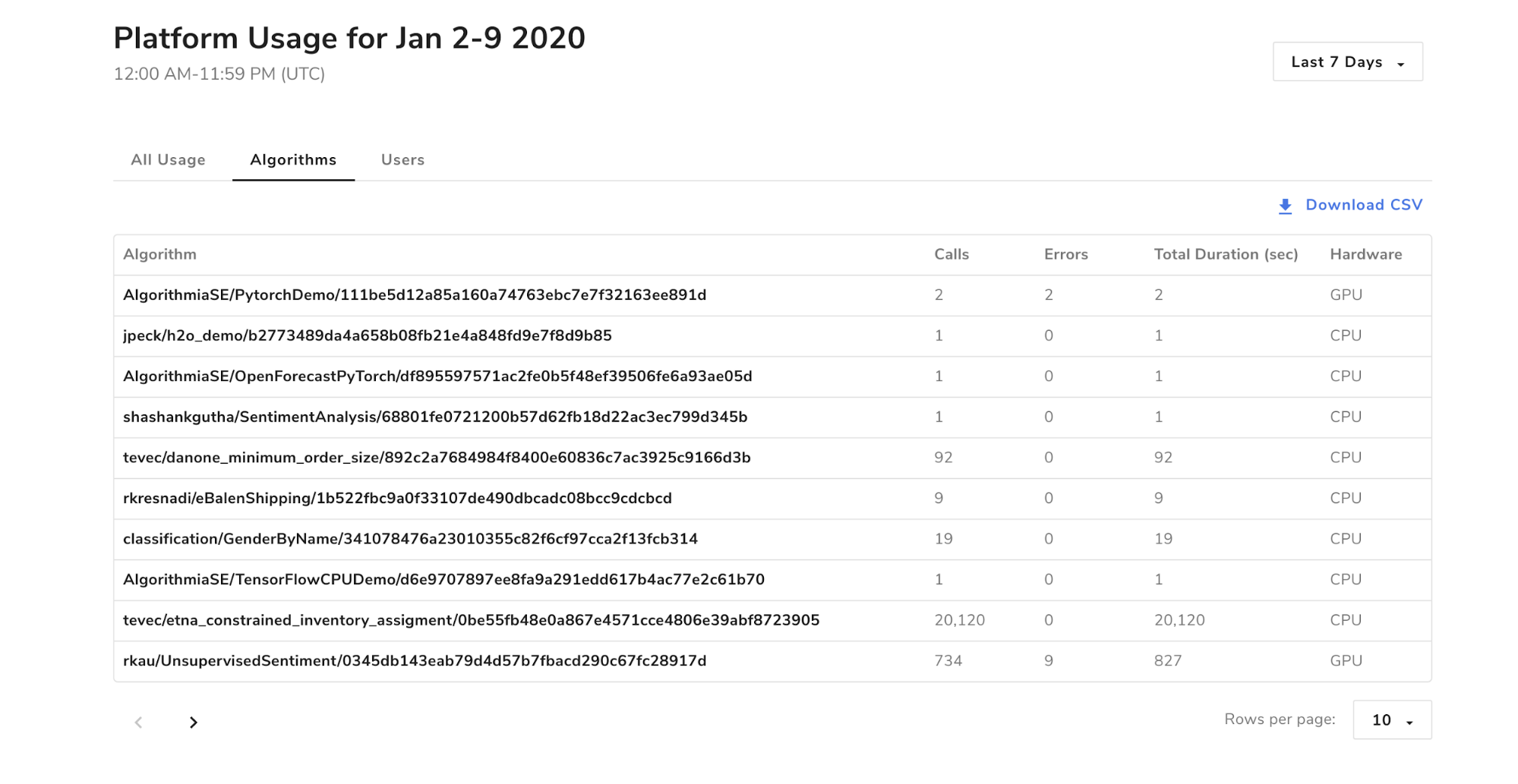
When you click on a row in the algorithms table, you will see this complete set of columns:
- algorithm: algorithm display name
- version: hash version of the exact algorithm called
- owner: user who created and owns the algorithm
- total calls: total number of calls that users of the platform made to this algorithm
- total duration: total number of seconds the algorithm ran summed up across all users
- total errors: total number of errors this algorithm returned summed up across all users
- error duration: total number of seconds the algorithm ran calls in which it returned an error (summed up across all users)
- hardware: whether the algorithm runs on a CPU or GPU instance
Users
This tab shows usage information grouped at the user level, so you can see how many total calls each user made (across all algorithms).
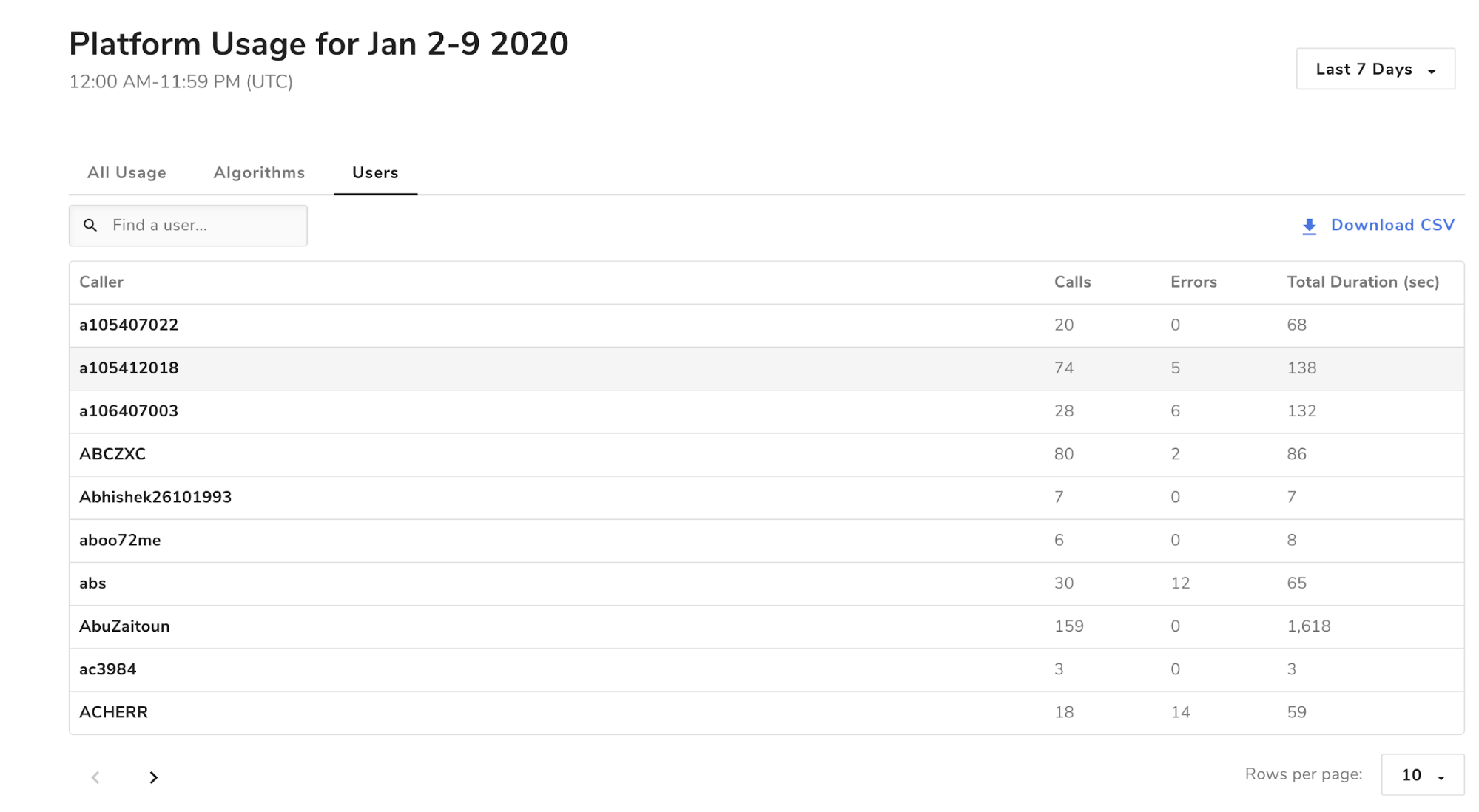
When you click on a row in the users table, you will see this complete set of columns:
- caller: the username of the user this row represents
- total calls: total number of calls the user made summed up across all algorithms
- total duration: total number of seconds the user’s calls spent computing summed up across all algorithms
- total errors: total number of errors returned to the user summed up across all algorithms
- error duration: total number of seconds computed by calls that returned errors to the user
Users wanting to perform more advanced operations on the tables (like sorting, customized grouping and summing) can download the full tables as CSV files.
Other quarterly update
API Key Terminology
There are two updates to API key terminology this release.
First, we no longer refer to our standard API keys as “Simple API Keys.” They are now simply “API Keys.”
Second, “Management API Keys” has been changed to “Admin API Keys.” This naming better fits the purpose for which these keys were designed, and is intended to minimize confusion for our enterprise administrators.
Enterprise Release Notes 19.10
Algorithmia’s 19.10 release featured a platform performance update and bug fixes for specific enterprise users. For more information, contact your Customer Success Manager.
Enterprise Release Notes 19.08
Algorithmia’s 19.08 release featured security updates for enterprise users. For more information, contact your Customer Success Manager.
Enterprise Release Notes 19.05
New this quarter:
- Jupyter Notebook integration
- Event-driven algorithm runs
- Additional APIs
- Additional IPA package sets
- Organization-hosted data
- Enterprise UI customization
Jupyter Notebook Integration
Data scientists can now deploy to the AI Layer directly from a Jupyter Notebook completing the entire data science life cycle—model training, visualization, and deployment—without ever leaving their Notebook.
Our updated APIs enable easier integrations like this and Zapier (from the last release), and we will be offering more endpoints moving forward. Please don’t hesitate to suggest tools you’d like to integrate.
Event-Driven Algorithm Runs
Event listeners allow external services to trigger actions such as model runs within the AI Layer. The first of our supported event sources is Amazon SQS, with a tutorial available in our Developer Center.
Additional APIs
New APIs allow you to create, recompile, and publish models directly from CI/CD pipelines, without using the Web API.

Additional IPA Package Sets
As introduced in the 19.01 release, We now enable more flexible instances and support new machine learning frameworks with many different combinations. New package sets execute faster and support a wider range of developer choices.
Our shift towards package sets allows the platform to iterate faster and increases the performance of algorithm runtimes. This allows the Algorithmia cluster to target package sets toward tailored scenarios.
We’re delivering a continuous stream of new sets, so check back for the latest versions often.
Organization-Hosted Data
A new data-browsing UX makes it even easier to browse and share data and models within your organization.
Organizations allow teams of customers to work in a private subset of models, moderate model publishing, and organize models into logical groups based on teams. This feature makes an organization more powerful by coupling the algorithms with the data necessary for models.
To view your hosted data, click on Data Sources in the main toolbar, then select an organiation. From here, browse the organization’s collections as you would your own data collections.
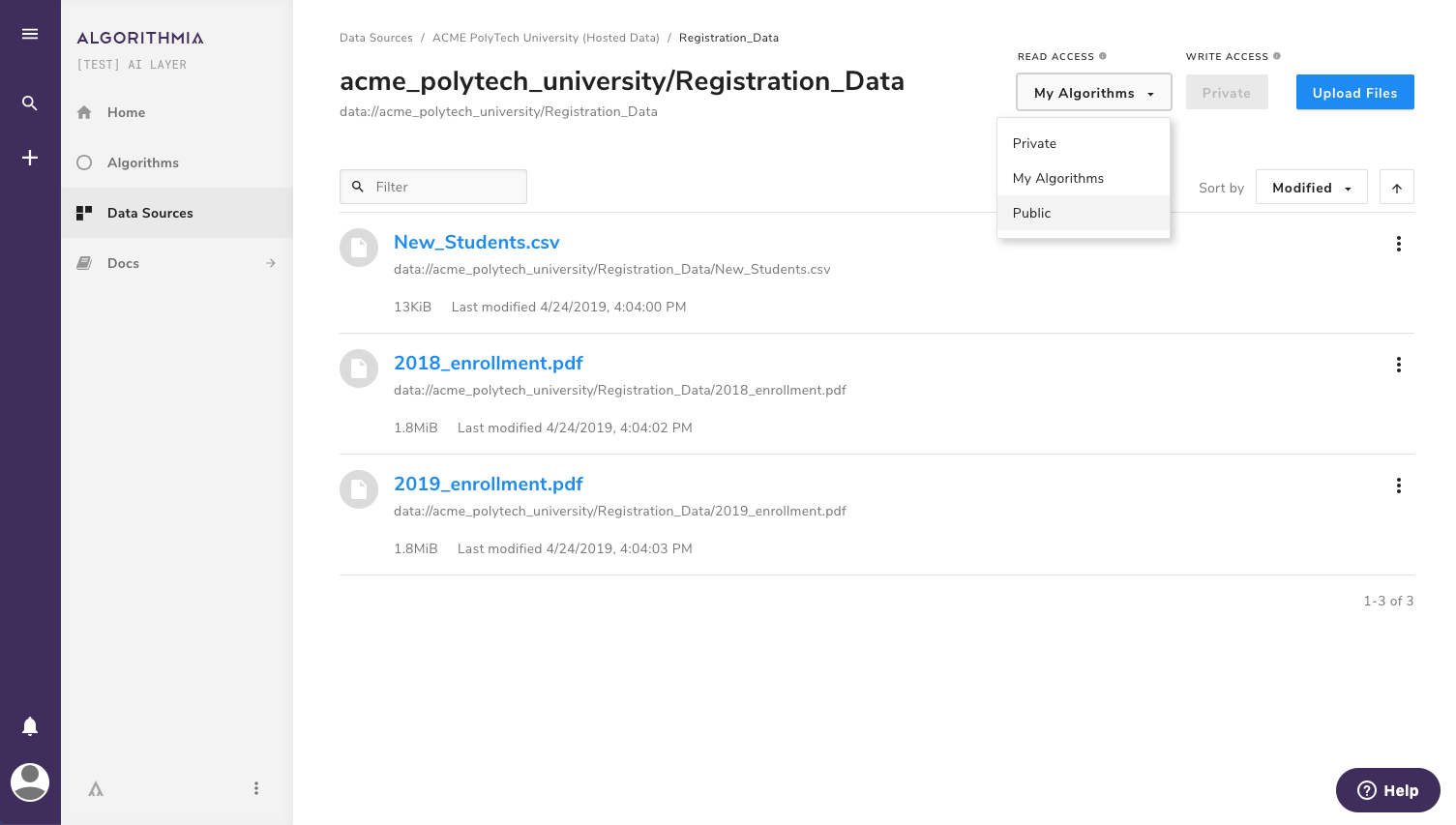
Organization data collections have the same permissions as user data collections, including:
Private Read: Only members of the organization may access the data, either directly or via an algorithm.
My Algorithms Read: Any caller may access the data of organization-owned algorithms, but only organization members may directly view the data.
Public Read: Anyone may interact with the data.
Private Write: Only members of the organization may write to the collection. This is the only available write setting.
Enterprise UI Customization
Enterprise customers now have the ability to tailor the UI of their AI Layer instances to their corporate brands.
What can now be customized:
- Brand Color
- Logo
- Favicon
- Navigation Title (Title that appears in browser tab)
- Header Title (Title that appears beneath logo)
- Title Of Sidenav Buttons
For questions and requests, please contact us at support@algorithmia.com.
Enterprise Release Notes 19.01
Algorithmia is moving into the new year with a lot of great improvements to the platform. We are always looking to increase performance in production model serving and infrastructure efficiency in every release while making the day-to-day developer and data scientist experience even more seamless.
Projects for this release focused on providing greater flexibility and data connectivity options and enabling queuing for user calls. These updates are part of our dedication to continuously improve our platform for our users. We’ve made a number of changes under the hood that will provide tangible boosts to speed, flexibility, and supportability.
New this quarter:
- Image per algorithm
- Algorithm APIs
- Support for .NET Core and .NET Standard
- Update algorithm settings
- New data storage connectors
- User work limits and queuing
Image Per Algorithm
We are really happy to announce the release of a major evolution to the architecture of how algorithm containers are created and loaded when requested on the Algorithmia platform. We now enable more flexible instances and support new machine learning frameworks with many different combinations.
New framework releases will be quickly added to allow data scientists and developers to take advantage of the latest technologies available to them.
Image Per Algorithm changes how algorithm version container images are created and shifts the creation of containers to when the algorithm changes instead of when a request comes in for the algorithm and a slot needs to be loaded. This shift towards package sets enables the platform to iterate faster and support emerging technology, and it increases the performance of algorithm runtimes.
This allows the Algorithmia cluster to target package sets toward tailored scenarios, like running a specific version of Tensorflow with Python 3.7. There is a package set available that is pre-configured for that scenario that will work in GPU and CPU environments.
The Algorithmia team will be creating new package sets in future releases and over time will transition all class algorithm base templates to new Image Per Algorithm-based package sets.
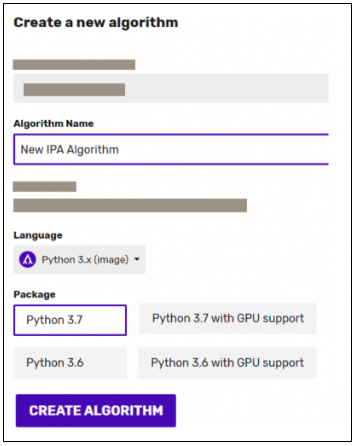
New package sets will be released to the Hosted Service on Algorithmia first and then rolled up together in future quarterly releases for Algorithmia Enterprise.
If you are interested in any package sets that have been released to the Hosted Service, please let your Deployment Architect know to work on getting it imported before your next upgrade.
Initial Package Sets for This Release
This release includes the following package sets that can be used for newly created algorithms going forward. New package sets will be created and shipped to the Algorithmia Hosted Service and bundled into future releases of Algorithmia Enterprise.
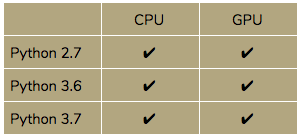
We will enable Enterprise Admins to create custom package sets to help provide best practices and templates for their data science teams specific to their organization.
Algorithm Management
Building on the previous release, we are expanding the available set of APIs that developers and system administrators can use to interact with the Algorithmia platform through automation. The main scenarios we heard customers want to automate with these newly available APIs are to enable continuous integration and continuous delivery pipelines.
We’re happy to say that the last two steps in an automated pipeline are no longer exclusive to the Algorithmia UI.
The additional APIs that have been added in this release are:
- Create algorithm
- Get algorithm information
- Update algorithm
- Publish algorithm
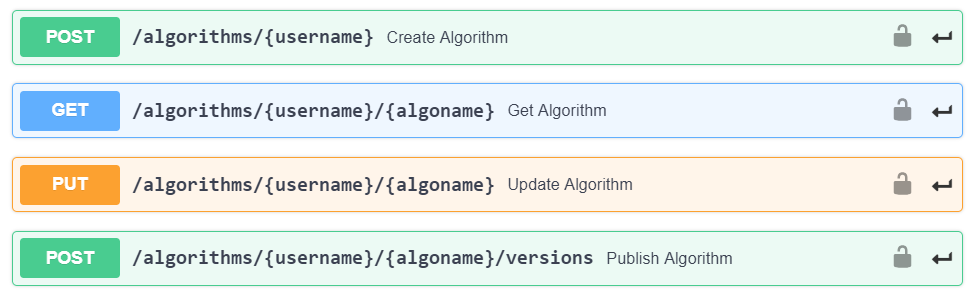
These algorithm APIs do not require admin API keys to use. Non-administrator users of an Algorithmia platform will be able to use their API keys to interact with algorithms they have permissions to work with. The use of admin API keys will not be supported by these algorithm APIs.
You can find the details for each of these APIs available in the OpenAPI spec.
The OpenAPI spec allows developers to generate language-specific clients through code generators, test APIs, interact with APIs more easily. It can even generate a Postman collection that can be imported into your Postman workspace. You can find many of these tools on the OpenAPI website.
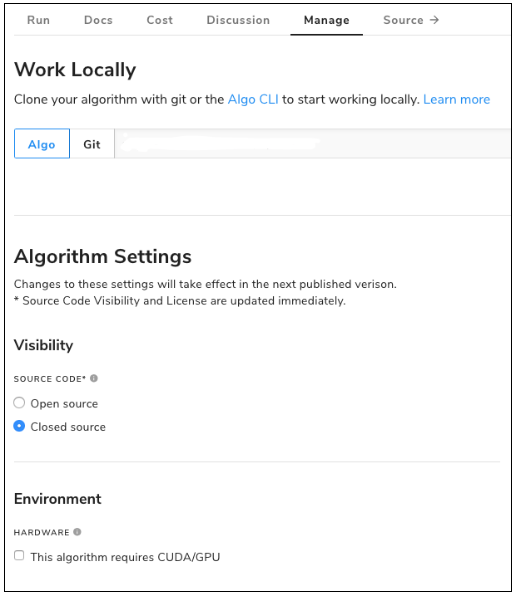
Update Algorithm Settings
Administrators and data scientists asked for a way to be able to update an algorithm’s settings without going through a full publish. For example, many users wanted to update their algorithm’s network access permissions or change the source code visibility after creating it.
Each of these settings and more is now available on the Manage tab of each algorithm. Most of the settings will apply immediately so data scientists can test private, unpublished versions.
However, to make settings changes available to developers consuming your algorithm, you’ll need to go through a full publish.
The two immediate settings that don’t require a publish are Source Visibility and License:
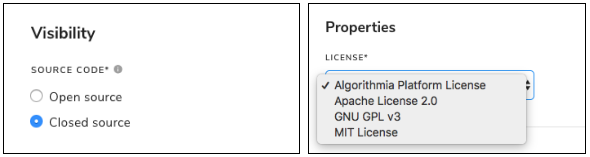
How to Update Algorithm Settings
During the publishing process, we’ll detect which settings will be changed for the next published version and inform the publisher the type of Semantic Versioning increase that will be required.
Note: All previous versions of a published algorithm are immutable and unable to be changed in order to help developers who are already using a specific version in their production apps.
New Data Storage Connectors
This release includes two new data storage connectors to allow data scientists and developers to leverage additional input and output locations for algorithms.
The data connector system allows an Algorithmia instance to securely handle brokering connections between an algorithm and a data source provided by the developers without needing to provide connection credentials.
Additionally, since it’s a single data API for the algorithm developer, access to an underlying data source is abstracted, allowing for algorithm developers to support many types of data sources without needing to implement provider-specific logic.
The two data connectors that are included in this release are:
To find out more information about the Data API available in each Algorithmia instance, including the Hosted Data Service, you can visit the overview topic in the Developer Center.

Algorithmia .NET SDK Supports .NET Core and .NET Standard
Customers have been adopting and transitioning to .NET Core and have been asking us to transition from only supporting the .NET framework. We’re happy to now include support for the Algorithmia .NET Client in all of the frameworks supported by .NET Standard 2.0, which includes .NET Core. This means that many more application types can run across Windows, Linux, MacOS, and mobile, and other devices will be able to directly make calls to algorithms.
Supporting .NET Standard 2.0 provides support for the following frameworks:
- .NET Core
- ASP.NET Core
- .NET Framework (>4.6.1)
- Mono
- Xamarin.iOS
- Xamarin.Mac
- Xamarin.Android
- Universal Windows Platform Apps
- Unity
All of the Algorithmia Clients are open-sourced on GitHub. You can follow the .NET Client on the GitHub website.
To get going, you can install the updated NuGet package for the Algorithmia .NET Client and follow the walkthrough available in the Developer Center.
Install-Package Algorithmia.Client
Flexibility to Enable User Work Limits and Queuing
Administrators need the flexibility to tune an algorithm’s usage of infrastructure while still running in production. Algorithmia has had the ability to provide “sticky slots” as one such flexibility example. This release introduces a new flexibility option to specify work limits for a particular user running production workloads.
This option will set limits to accept calls from a user but will begin queueing requests that are above the maximum active jobs limit until the maximum concurrent sessions are reached. The setting is available on the Advanced options page of the Admin Panel by clicking the “Update User’s Work Limits” button.
Administrators now have the flexibility to manage an algorithm’s use of their cluster. In one Algorithmia cluster, administrators were able to see a 30-percent decrease in monthly infrastructure costs by being able to finely tune production algorithms.
How to Update a User’s Work Limits

User to Update: Enter the username of the user you want to limit. Max Concurrent Sessions: Input a max number of concurrent requests a user can make at one time to ensure resources are not being over allocated. Max Active Jobs: Insert a max number of active jobs a user can have before requests begin queueing to ensure other users have resources available to them.
