 Python
PythonBefore you get started learning about Python algorithm development, make sure you go through our Getting Started Guide to learn how to create your first algorithm, understand permissions available, versioning, using the CLI, and more. In this guide we’ll cover algorithm development for Python in more depth, including making use of Algorithmia’s Algorithm Development Kit for Python.
Table of Contents
- What is an Algorithm Development Kit (ADK)?
- Algorithm project structure
- Hello world
- Loaded state
- Available libraries
- Managing dependencies
- I/O for your algorithms
- Calling other algorithms
- Error handling
- Algorithms with multiple files
- Publishing Algorithmia Insights
- Algorithm checklist
- Publish algorithm
- Conclusion and resources
What is an Algorithm Development Kit (ADK)?
An Algorithm Development Kit is a package that contains all of the necessary components to convert a regular application into one that can be executed and run on Algorithmia. To do that, an ADK must be able to communicate with Algorithmia’s langserver service. To simplify development, an ADK exposes some optional functions, along with an apply() function that acts as the explicit entry point into your algorithm. Along with those basics, an ADK also exposes the ability to execute your algorithm locally, without langserver, which enables better debuggability.
Algorithm project structure
Algorithm development begins with your project’s src/Algorithm.py file, where you’ll import the Algorithmia ADK and implement the required functions. Each algorithm must contain an apply() function, which defines the input point of the algorithm. We use the apply() function in order to make different algorithms standardized. This makes them easily chained and helps authors think about designing their algorithms in a way that makes them easy to leverage and predictable for end users. When an algorithm is invoked via an API request, the body of the request is passed as input to our apply() function.
Optionally, an algorithm can also have a load() function, where you can prepare your algorithm for runtime operations, such as model loading, configuration, etc.
Algorithms must also contain a call to the handler function with your apply() and optional load() function as inputs. This will convert the project into an executable, rather than a library, which interacts with the langserver service on Algorithmia while also being debuggable via stdin/stdout when executed outside of the Algorithmia platform. An init() function starts the algorithm and allows you to provide an input for use when the algorithm is executed locally, bypassing stdin parsing and simplifying debugging by alleviating the need to execute your code on the Algorithmia platform. You can also step through your algorithm in your IDE of choice by executing your src/Algorithm.py script.
If youre a PyCharm user, you can refer to this guide to set up your IDE.
Let’s look at an example to clarify some of these concepts.
Hello world
Below you’ll find a src/Algorithm.py file which prints “hello” plus an input when it is invoked. We start by importing the Algorithmia ADK, and then defining our apply() function, followed by our call to the handler function ADK(), and finally calling init() to start the function.
from Algorithmia import ADK
def apply(input):
return "hello {}".format(str(input))
algorithm = ADK(apply)
algorithm.init("Algorithmia")When executed on the Algorithmia platform and providing the string “HAL 9000” as an input, this algorithm will output “hello HAL 9000”. If executed locally, such as during development or debugging, the algorithm will print hello Algorithmia to stdout instead.
Loaded state
When an algorithm is called, our platform checks whether there’s already a running instance that’s ready to handle the request, or whether a new one needs to be created. Spinning up a new algorithm instance involves overhead, and this can be substantial for algorithms with extensive code dependencies, or algorithms that need to load a significant amount of data into memory. Developing with an ADK allows you to make use of an optional load() function for preparing an algorithm for runtime operations, rather than performing these operations each time the algorithm is invoked.
Using load(), we can load state into memory prior to a function’s execution, and then access that data each time the algorithm is executed and the apply() method is called. We do this by returning a globals object in our load() function and passing that object as an additional parameter to the apply() function.
Let’s add a load() function to the Hello World example we just created:
from Algorithmia import ADK
def apply(input, globals):
return "hello {} {}".format(str(input), str(globals['payload']))
def load():
globals = {}
globals['payload'] = "Loading has been completed."
return globals
algorithm = ADK(apply, load)
algorithm.init("Algorithmia")In our load function we’ve created a globals object and added a key called payloads with a string value Loading has been completed.; we then return the globals object, which will be passed as input to the algorithm’s apply() function, where we use that value as part of the algorithm’s output. Executing the algorithm locally will result in hello Algorithmia Loading has been completed. being printed to stdout.
If a failure occurs while executing the load() function, the platform will raise a loadingError.
Available libraries
In addition to your own code in src/Algorithm.py, Algorithmia makes a number of libraries available to make algorithm development easier. We support multiple versions of Python and a variety of frameworks, and we continue to add new variants and broaden GPU support. A complete list of predefined environments can be found on the Environment Matrix page, and are available through the “Environment” drop-down when creating a new algorithm.
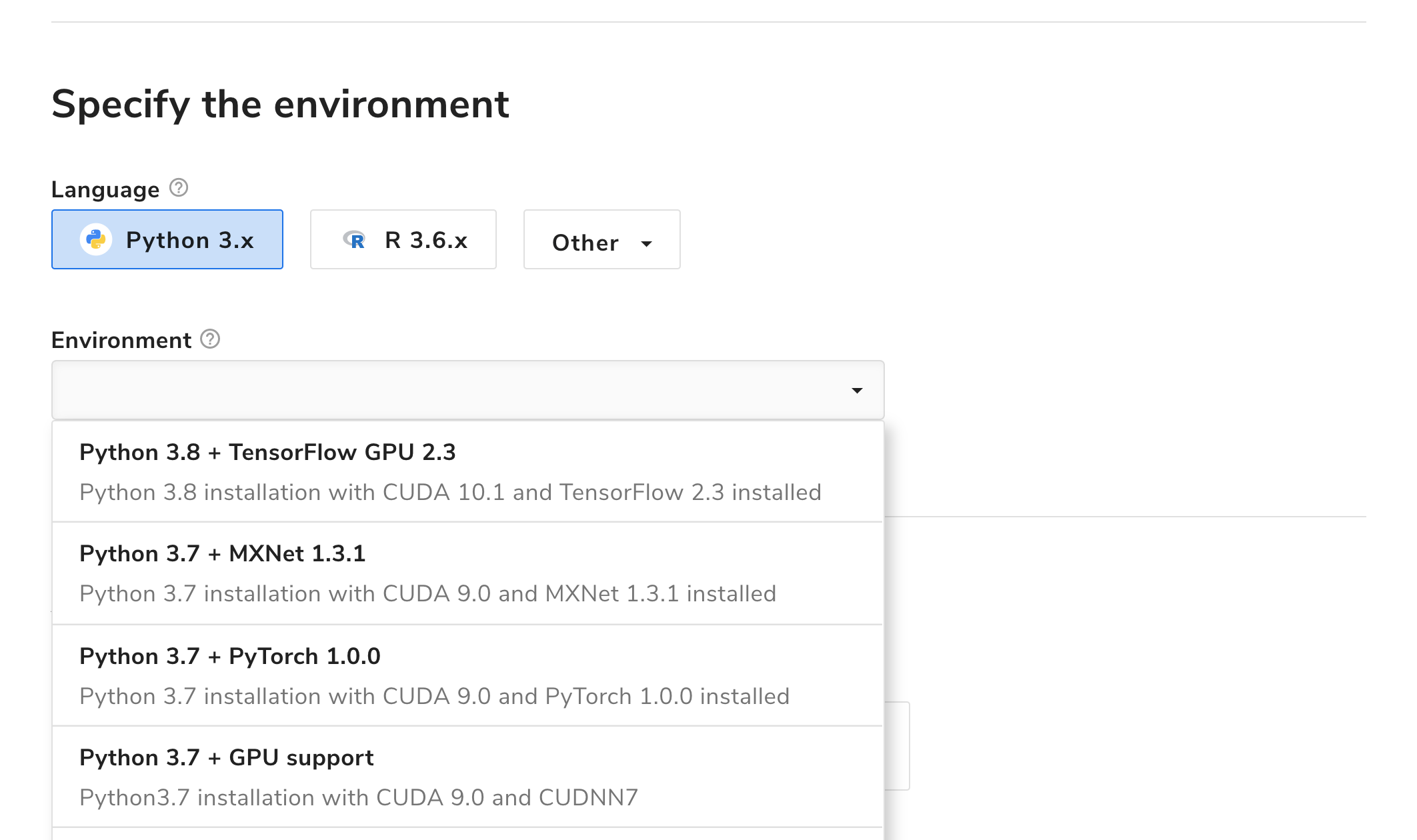
In addition to the libraries and ML frameworks that we make available in our predefined environments, you can utilize any other open-source packages, including Scikit-learn, Tensorflow, NumPy, and many others by adding them as a dependency in your algorithm.
Also, algorithms can call other algorithms and manage data on the Algorithmia platform. You can learn more about calling algorithms in the Algorithmia Python Client Guide.
Managing dependencies
Algorithmia supports adding third-party dependencies via the Python Package Index (PyPI) using a requirements.txt file, where you can add the names of any dependencies you have. If you do add dependencies, you will still need to import those packages via the import statement to your algorithm file as you would do for any Python script.
For example, to make use of numpy, you would include the line:
numpy
in the dependencies file and the line
import numpy as np
in the main file.
If you’re using Python 3, the syntax has changed for imports. You’ll need to use:
from .somefile import * instead of in Python 2 where it’s from file import *.
I/O for your algorithms
Algorithm input is standardized across the Algorithmia platform. Algorithms take three basic types of input: strings, JSON, and binary data. You will need to parse the algorithm’s input as part of your apply() or load() functions.
Working with basic data structures
Below is a code sample showing how to work with basic user input in the apply() function. You’ll also see some error handling, which we’ll cover in more detail in the Error Handling section of this guide. Our input to this function is as follows:
{"numbers": [1, 4, 2, 6, 3]}First, we’ll check that the key numbers exists in the input and that it contains a list of numbers. We can then get the values, process them, and return a result.
def apply(input):
"""Finds the minimum and maximum numbers in a list."""
# Check for numbers field and make sure it contains a list.
if "numbers" in input and isinstance(input["numbers"], list):
# Get the value of the field "numbers"
user_list = input.get("numbers")
try:
user_max = max(user_list)
user_min = min(user_list)
return {"min_num": user_min, "max_num": user_max}
except TypeError as e:
print("Please use numeric data types in your list: ", e)
else:
# Raise helpful error message
raise AlgorithmError(
"Please provide a valid input that includes an array of numbers in the field 'numbers'")If we were to run this code as part of our algorithm, we should see the minimum and maximum of the numbers in the list returned in the console:
{"max_num":6, "min_num":1}Working with data stored on Algorithmia
This next code snippet shows how to create an algorithm that works with a data file stored in a Hosted Data Collection on Algorithmia.
Files stored in Hosted Data must be transferred into the algorithm before use, via the getFile method. Alternately, their contents can be transferred using getString, getJson, or getBytes.
In this example we’ll provide a Data URI for the file as the input to our algorithm. We can then make use of the Algorithmia Python Client to retrieve the contents of the file, split that text into sentences, and then split the sentences into words.
First, make sure to add an import for the Python client into your algorithm and instantiate the client within the load() function:
import Algorithmia
def load():
# Note that you don't pass in your API key when creating an algorithm
client = Algorithmia.client()Next, we’ll parse the input as part of our apply() function, checking for the user_file field and then getting the contents of the file and parsing them:
def apply(input):
"""Take a user file holding text content and returns text split into words."""
# Check if the file exists in the user specified data collection.
if "user_file" in input and client.file(input["user_file"]).exists():
user_file = input["user_file"]
# Get the contents of the file as a string.
text = client.file(user_file).getString()
# Split text into lists of sentences
sentences = text.split(".")
# Split up each sentence into words.
words = [item.split(" ") for item in sentences if len(item) > 0]
# Return dictionary of original text and the sentences broken up into their separate words.
return {"text": text, "words": words}
else:
# Raise helpful error message
raise AlgorithmError("Please provide a valid input")If you use this code in your own algorithm, you can test it by passing in a file that you’ve uploaded to a Data Collection. The code above will return both the original text and the list of each sentence split up into words.
When you are creating an algorithm be mindful of the data types you require from the user and the output you return to them. Our advice is to create algorithms that allow for a few different input types such as a file, a sequence or a URL.
Working with directories
While running, algorithms have access to a temporary filesystem located at /tmp, the contents of which do not persist across calls to the algorithm. While the Data API allows you to get the contents of the files you want to work with as JSON, a string, or raw bytes, in some cases you might need your algorithm to read and write files locally. This can be useful as a temporary location to store files downloaded from Hosted Data, such as raw data for processing or models to be loaded into your algorithms. It can also be used to write new files before uploading them via the Data API.
For reference, this gist provides an example of iterating over data in a directory, processing it, and writing new data to a file, while this template for ALBERT and Tensorflow provides an example of using the /tmp directory to load a model.
Writing files for the user to consume
Sometimes it is more appropriate to write your output to a file than to return it directly to the caller. In these cases, you may need to create a temporary file, then copy it to a Data URI (usually one which the caller specified in their request, or a Temporary Algorithm Collection):
# {"target_file":"data://username/collection/filename.txt"}
file_uri = input["target_file"]
tempfile = "/tmp/"+uuid.uuid4()+".tmp"
save_some_output_to(tempfile)
client.file(file_uri).putFile(tempfile)Calling other algorithms
To call other algorithms from your algorithm you can use the Algorithmia Python Client, which is automatically available to any algorithm you create on the Algorithmia platform. For more information on calling algorithms, you can refer to the Python Client Guide.
You may call up to 24 other algorithms, either in parallel or recursively.
Error handling
In the above code examples we made use of an AlgorithmError class which you should use for handling errors within your algorithm. This way the user can tell the difference between a standard Python library error and an error thrown by your algorithm:
class AlgorithmError(Exception):
"""Define error handling class."""
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value).replace("\\n", "\n")And then raise the error with a helpful error message:
raise AlgorithmError("Please provide a valid URL")Additionally, if you are creating an algorithm that relies on calling another algorithm you may use Algorithmia error messages for catching errors thrown by that algorithm:
import Algorithmia
def apply(input):
try:
print(algo.pipe(input).result)
except Exception as error:
print(error)
def load():
client = Algorithmia.client()
# An algorithm that takes a URL
algo = client.algo("util/Url2Text/0.1.4")For more information on error handling see the Better Error Handling Guide.
Algorithms with multiple files
Putting everything in one source file sometimes doesn’t make sense and makes code more difficult to maintain, so in many cases you’ll want to break your code into multiple source files. For example, you might have several utility functions related to establishing a connection with an external database and then reading and writing data using that connection. To keep your code modular, you might define this functionality in a separate file that you then import into your main algorithm file where the functions are actually called. The Algorithmia platform supports using multiple source files, but you’ll need to be aware that the import paths you use locally may differ from ours.
This means that if your project looks like this:
/
requirements.txt
algorithmia.conf
src /
__init__.py
Algorithm.py
secondary_file.py
sub_module /
__init__.py
special_stuff.py
Your import code might look something like this:
from Algorithmia import ADK
import Algorithmia
import os
from secondary_file import auxillary_func, some_other_func
from sub_module.special_stuff import special_stuff
This will work fine for Python 2. However, for Python 3, you need to use the dot-prefix notation for local files:
from Algorithmia import ADK
import Algorithmia
import os
from .secondary_file import auxillary_func, some_other_func
from .sub_module.special_stuff import special_stuff
Publishing Algorithmia Insights
This feature is available to Algorithmia Enterprise users only.
Inference-related metrics (a feature of Algorithmia Insights) can be reported via using the report_insights method of the Algorithmia client.
Depending on your algorithm, you might want to report on the algorithm payload for each API call (such as the features or number of features), the output of the algorithm to monitor data distributions of predictions, or probability of each inference.
In the case of an example credit scoring model, shown in this demo for Algorithmia Insights, reported metrics include the algorithm predictions:
# Report Algorithmia Insights
client.report_insights({"risk_score": risk_score, "approved": approved})# Sample model output that is pushed to Insights
{
"approved": 1,
"risk_score": 0.08
}Algorithm checklist
Before you are ready to publish your algorithm it’s important to go through this Algorithm Checklist and check out this blog post for Advanced Algorithm Development .
These resources provide important information on best practices, including how to write a good algorithm description and how to add links to external documentation.
Publish algorithm
Once you’ve developed your algorithm, you can publish it, which makes it available for others to use.
To learn how to publish your algorithm you can refer to the Algorithm Development Getting Started Guide.
Conclusion and resources
In this guide we covered the basics of the ADK, how to create an algorithm and work with different types of data, and learned how to publish an algorithm. You can find complete examples in the Algorithmia Python ADK repository on GitHub, inlcuding a Pytorch based image classification example.
You might also find the following resources useful when developing your own algorithms: